
Our PMA.core tile server is all about providing connectivity, and we talk a lot about how great we are in terms of:
- Supporting more WSI file formats than anybody else
- Supporting more storage media than anybody else
- Being able to integrate different annotations from environments like ImageJ or QuPath
- Being able to bring together a great variety of metadata
What we don’t boast about too often though are our audit trailing capabilities. It’s sort of our secret sauce really, that overlays everything that takes place within the PMA.core environment (and by extension really almost all of our other products, too).
The need for monitoring
Yes, we know that monitoring conjures all sorts of “Big Brother is watching you” memes, but there are a number of good reasons to provide this kind of service, too:
- When enrolling new users, you want to keep an eye out for them that they can do things as they are intended. Some of us are introverts, and some pre-emptive corrections (if needed) may actually be appreciated.
- Too many audit events may be a clue that there’s a security breach in your system, requiring other actions to be initiated.
- It’s a general sanity check for hard working staff that can now at the end of the day make sure that they indeed looked at everything they needed to, and that it was recorded as such.
- During an audit, or when an outlier event takes place, an audit trail can provide supportive evidence that indeed things did take place as intended.
- As a professor, you assign homework cases to your students. Did the student really go look at the assignment?
- In some cases, the features of an audit trail can be prescribed in the form of legal obligations (depending on your jurisdiction). One such example are the FDA’s 21CFR.11 guidelines.
An audit trail need not be a mystery, either. In essence, it means that for each change in any data point, you keep track of:
- Who did it
- When it happened
- Where it happened
- Why it happened
Correspondingly, if there’s no audit trail record of an operation, it didn’t happen.
Creating content
Let’s see how that is implemented in PMA.core. Let’s create a new user:
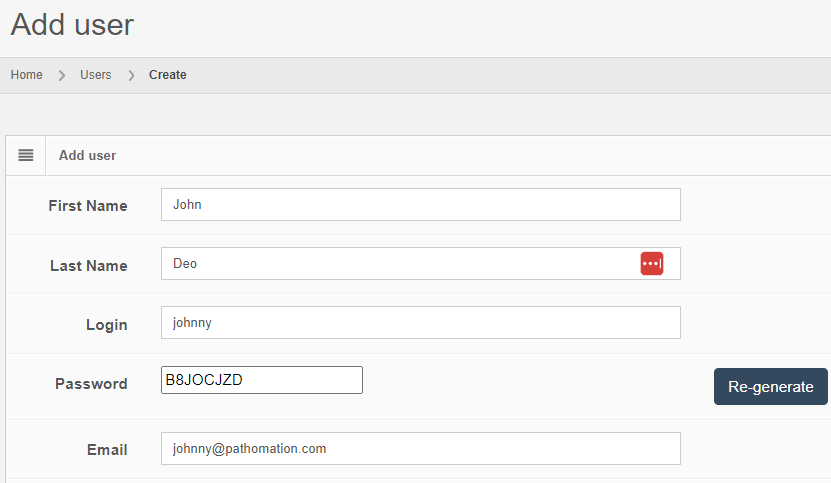
After you create the user, the “Audit trail” tab immediately becomes visible. When you click on it, you see that new data was entered.
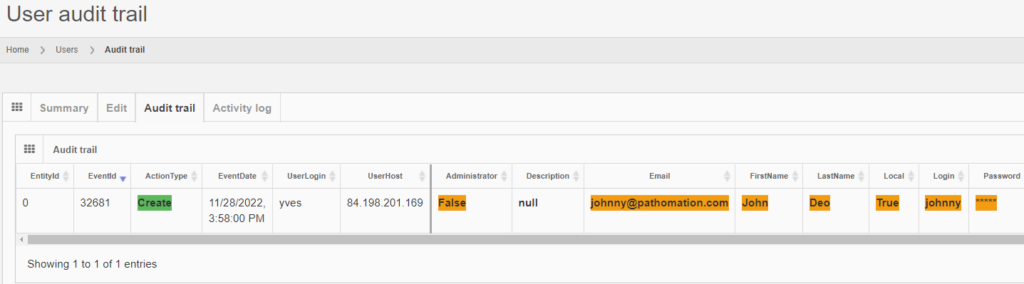
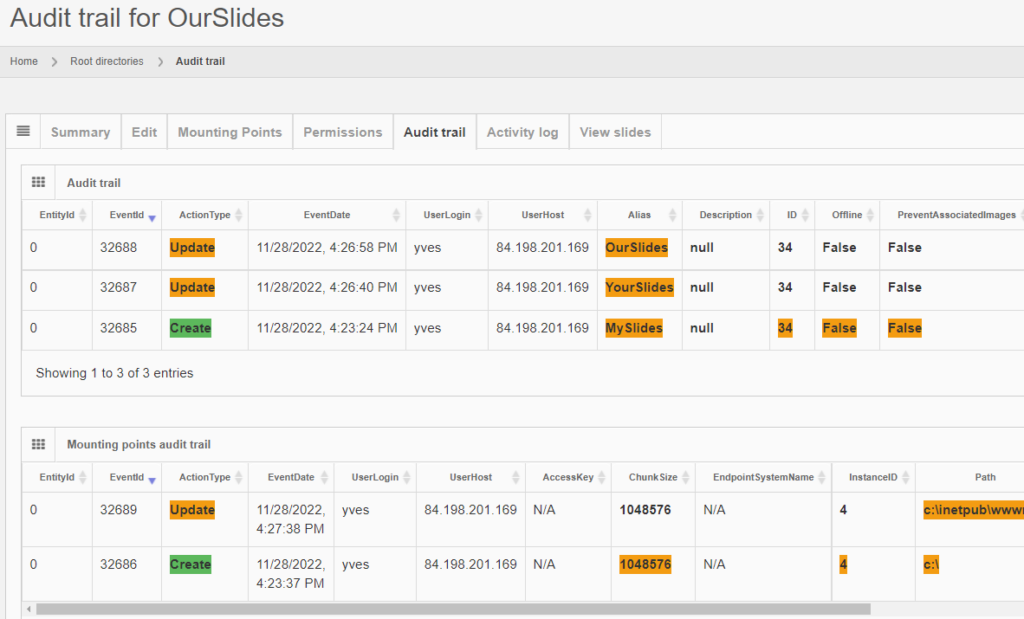
The same audit principle applies to other information types across PMA.core. For convenience, we sometimes combine different entities in a single report. An example is a root-directory: A root-directory always consists of a symbolic name (the root-directory itself), and one or more mounting points. You can’t have one without the other. So the audit trail for both is combined and shown as follows:
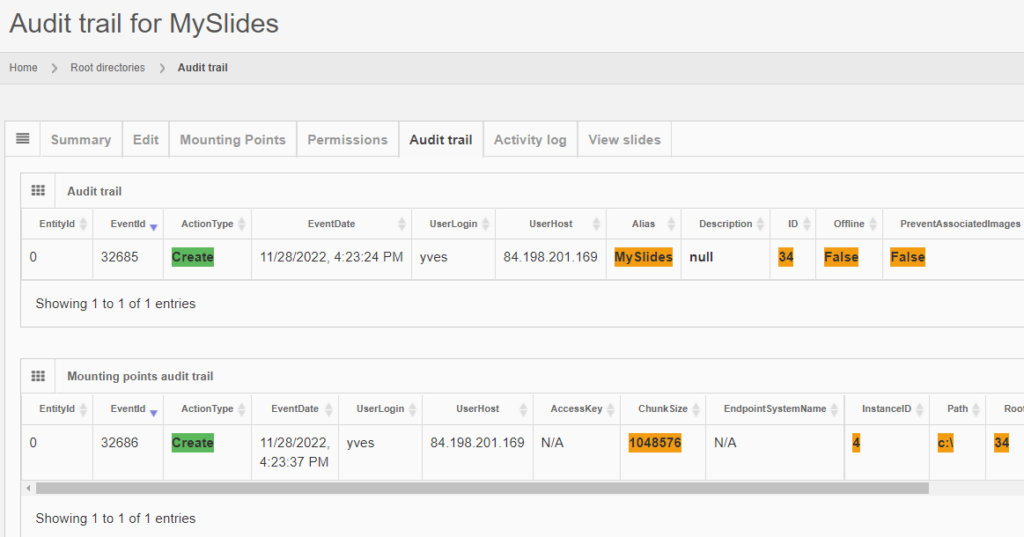
Note that sensitive and private information like someone’s password is still obscured, even at this level.
Editing content
Let’s make some changes to the user’s record:

The audit trail tab shows the changes:
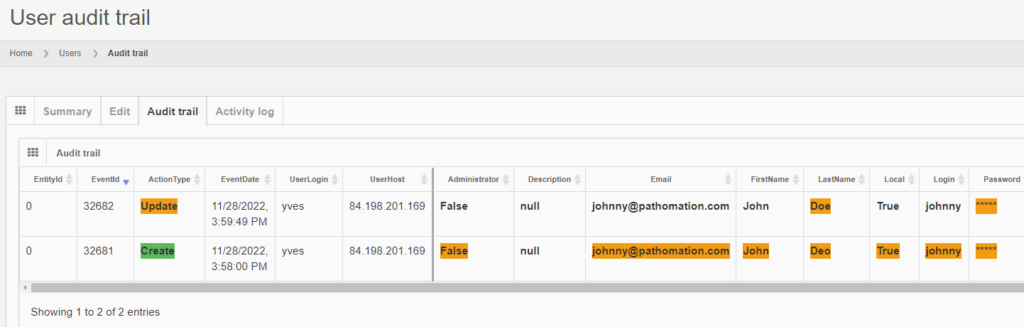
And the same principle applies to all entities, like the aforementioned root-directories. Note that multiple subsequent edits are shown as separate records:
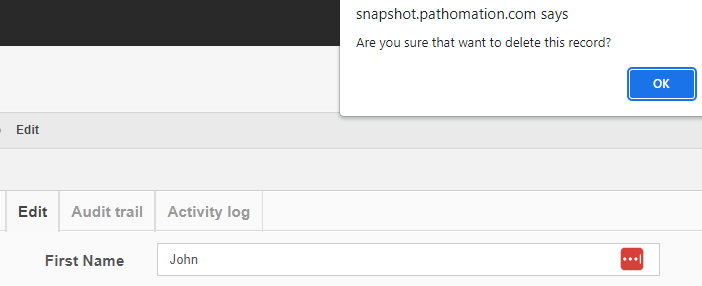
Deleting content
Getting rid of content is probably where the audit trail comes in the most useful.
After deleting a record, you can search for it, and the fact that no results are returned proves that as far as PMA.core is concerned, the record is indeed deleted.
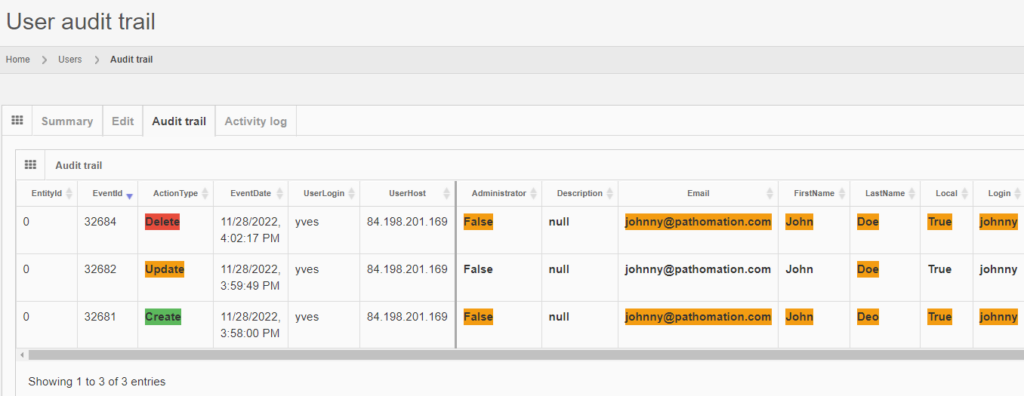
It is possible to transiently see the operation in retrospect, by typing in the direct URL to the entity’s original audit trail:

The red color is used to indicate that something final happened here:
However, when logging out of PMA.core, and logging back it, it’s harder to retrieve the data, as you need to remember to entity’s original identifier, and even if you do, it may be taken over by a new entity.
We’ll show you in a minute how to get access to deleted data in a more reliable and predictable way.
Why would you want to keep track of deleted data? Do you care to find out whether the student did his homework last semester? Probably not, but at least in the context of clinical trials, as well as hospital operations, this makes sense, because:
- Clinical trials can run for many years. For rare diseases, the phase I clinical trial can particularly stretch on for a long time. People switch jobs and roles in between, and when final approval of the drug approaches, it’s important to still have a track record of who was involved
- Regulatory at the country level often require patient data to be kept for dozens of years. Just as important as it is to keep the patient-data, are the meta-data describing the actions performed with the patient records.
Back-end database
PMA.core only offers audit trail views for the most commonly referenced data types. Whether you can consult the data through the PMA.core end-user interface or not; all operations on any data entities in PMA.core eventually are tracked through a single table structure, which is defined in our wiki:
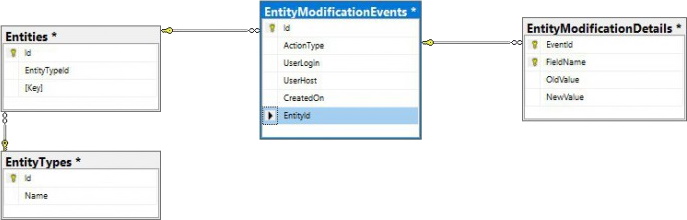
This means that even if there is no visual interface within PMA.core, or you can’t remember the original URL to the entity’s audit trail, there’s always the possibility to go dig into the audit trail in the back-end:
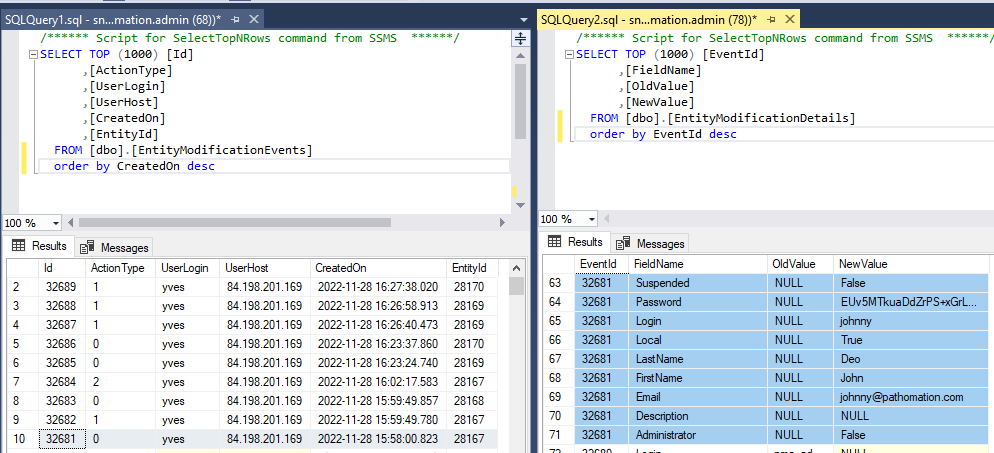
The above shows how the data from our first user record creation is represented. Below is what the update looks like:

And finally, the delete event:
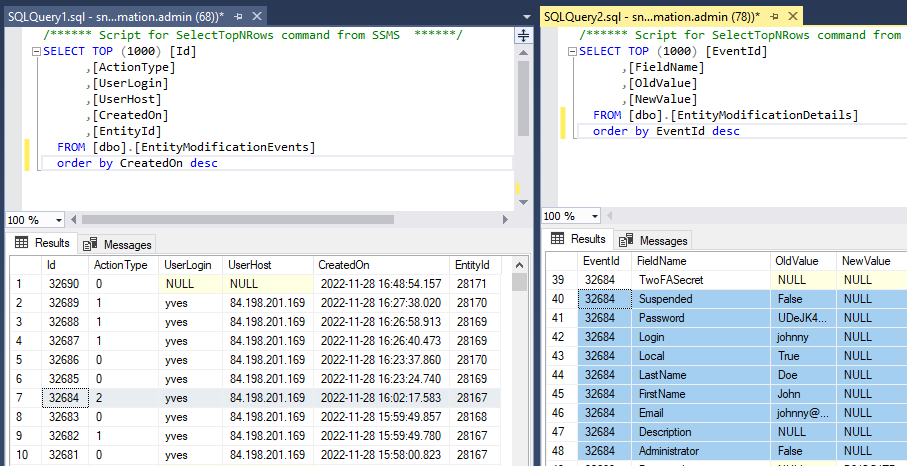
Scaling and resource allocation
All this extra data means extra storage of course. Microsoft SQL Server can definitely handle a lot of records, but there are still situations where extra care is warranted.
When a lot of data passes through the system transiently, it’s possible for the logfiles (tables) to grow quicker than the rest of the database. Consider that also annotations and meta-data (form data) is audit-trailed.
In order to give some guidance as to how much data there actually is, as well as when it was generated, the installation check view gives high-level statistics on this:
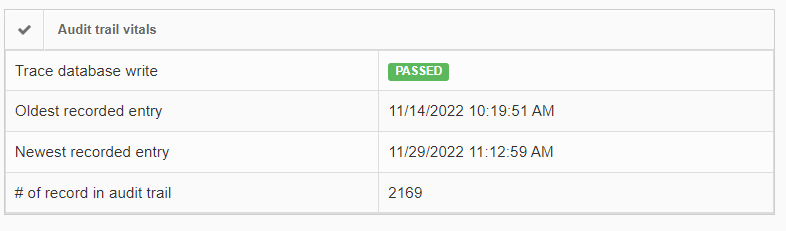
If the number of records in the audit trail increases rapidly, you should be able to explain why this is (many users, lots of annotation activities taking place, lifetime of the total installation…). It’s important also at that point to go through our latest recommendations on SQL Server compliance.
In closing
In an earlier article, we talked about the differences between adapting an open-source strategy versus a commercial platform like our own.
This article adds more substance to this discussion: to be truly prepared for enterprise-level deployment of digital pathology, it’s important to know who’s doing what with your system. It’s important to be able to prove that to the necessary stakeholders, including governments and regulatory agencies.
Pathomation’s PMA.core tile server then has all the necessary infrastructure to get you started off the right foot.