
This is part 3 in a series of software development. The earlier parts are available here:
- Part 1: Processes to facilitate a software development life cycle
- Part 2: The need for software validation
In this episode, we want to pick up where we left of, and discuss how a small company like ourselves, can effectively still have an efficient software validation process, without slowing things down and ending stranded in a hopeless bureaucracy.
Indeed it’s a bad joke that, once you have your software validated, (CE) certified, and government approved, you stop developing it any further, because the overhead (i.e. cost) of going through the whole process again, doesn’t justify the (typically small) incremental gains that are to be had from releasing a new version.
No Sir, at Pathomation we like to be creative and innovate, and we’ve always said that administration should not stand in the way of that. So what did we do? Like with our original software development itself, we looked at automation to provide part of the answer.
Remember the schematic from last time?
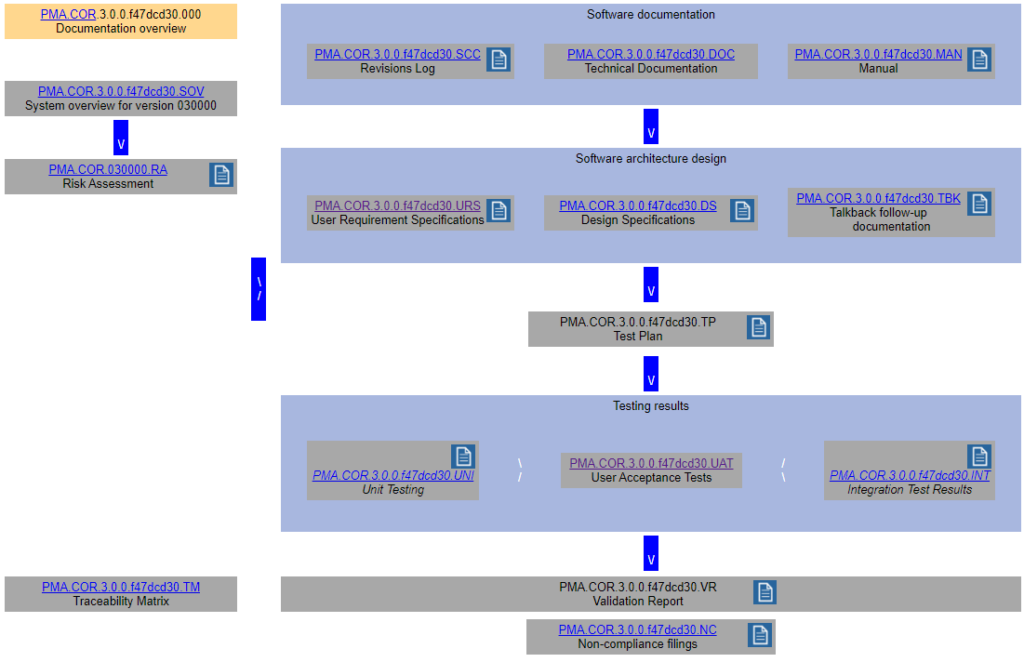
We came up with a whole datababase schema to put behind this and optimize workflow from one type of documentation to the next.
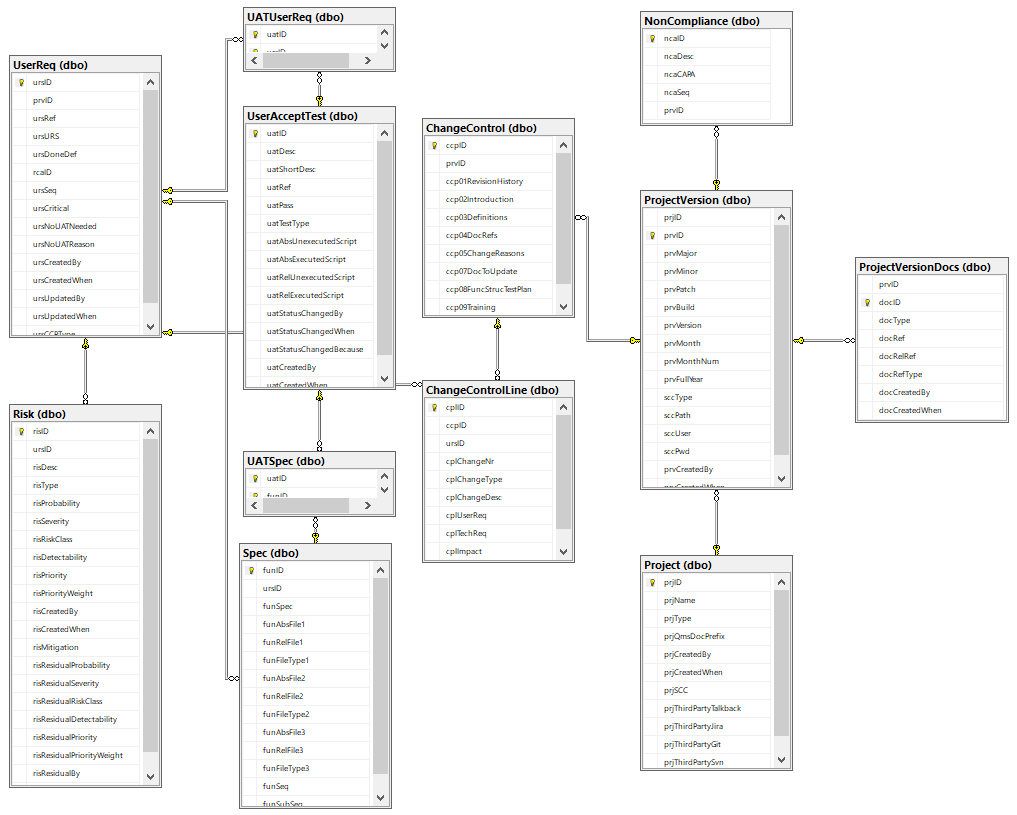
Custom granularity is what we’re after here, and we like to think we come pretty close!
Because SSMS isn’t known for user-friendly data entry, we also built a set of PHP scripts around it, so we can easily populate it (and most importantly: never have to worry about synchronizing Word-documents by hand again!)
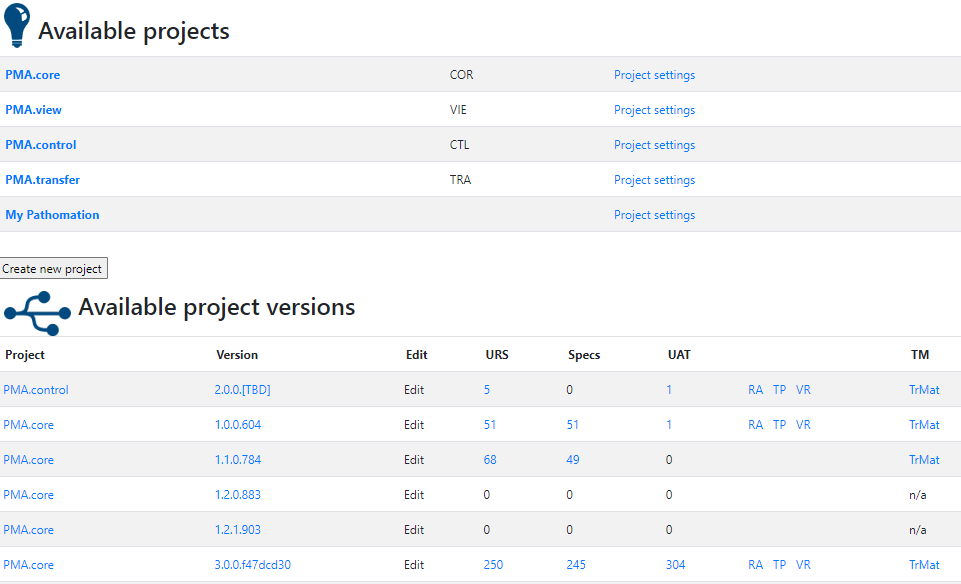
We’ll use parts of the PMA.core project for sample data and illustrate our approach throughout the rest of this article.
Oh, and if you’re curious about the other product names you see in the list: have a look at our product portal.
Requirements and specifications
One of the key documents to keep track of when developing software are the user requirement specifications (URS).
After writing out a general description of what our software is supposed to do (the System Overview document – .sov extension in the schema), we can start to capture in more granular detail what the different bells and whistles are going to be.
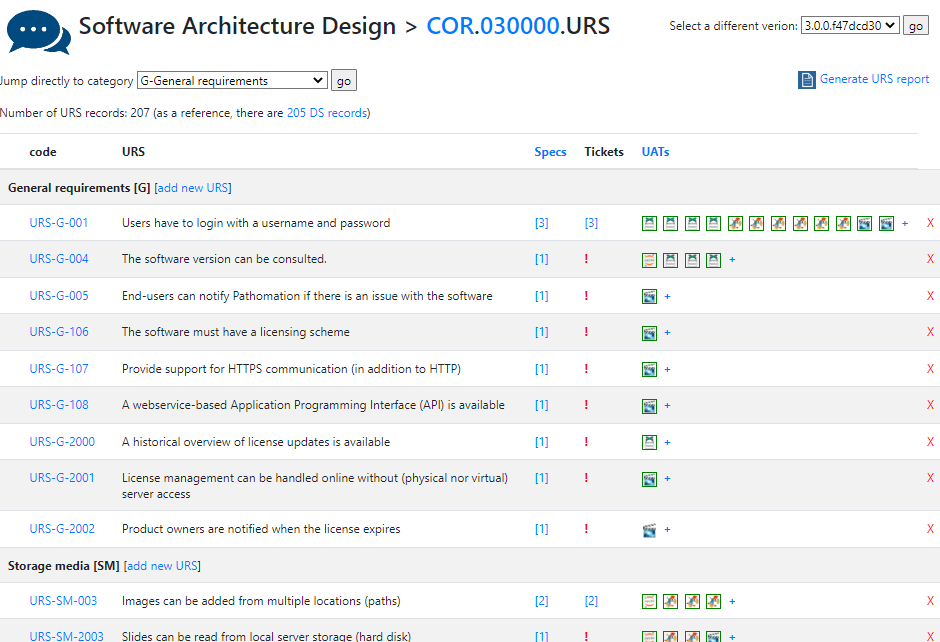
There’s a lot of room for interpretation at this level: Since PMA.core’s bread and butter is supporting as many different slide scanners as possible; Each file format is a separate URS entry.
For each URS, a specification is written up. Subsequently, tickets can be assigned to it. Tickets can originate from different locations:
Talkback is our historical original ticketing system based Corey Trager’s excellent BugTracker.Net project.
As we grew our team, we outgrew BugTracker and upgraded to Jira.
Features can be the result of a helpdesk-ticket. Keeping in mind what requirements originate from actual user requests (and not Pathomation’s CTO’s crazy brain) is useful to prioritize.
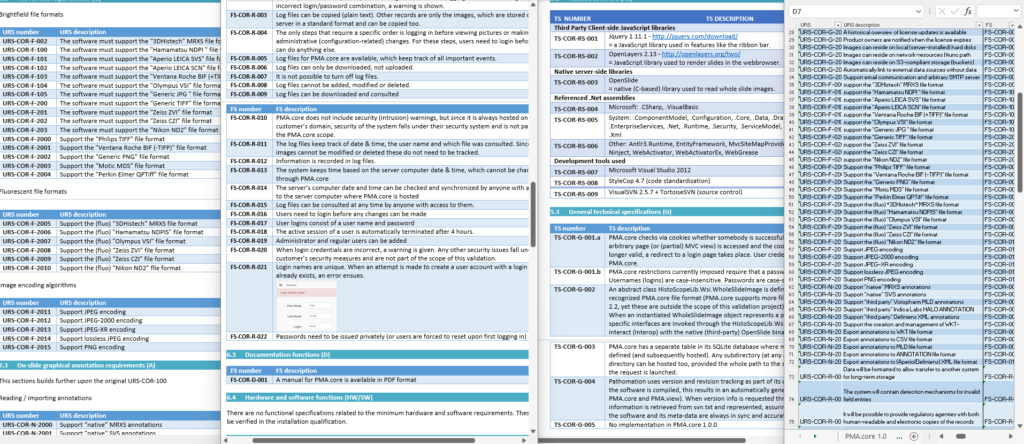
A completely annotated URS ends up looking like this:
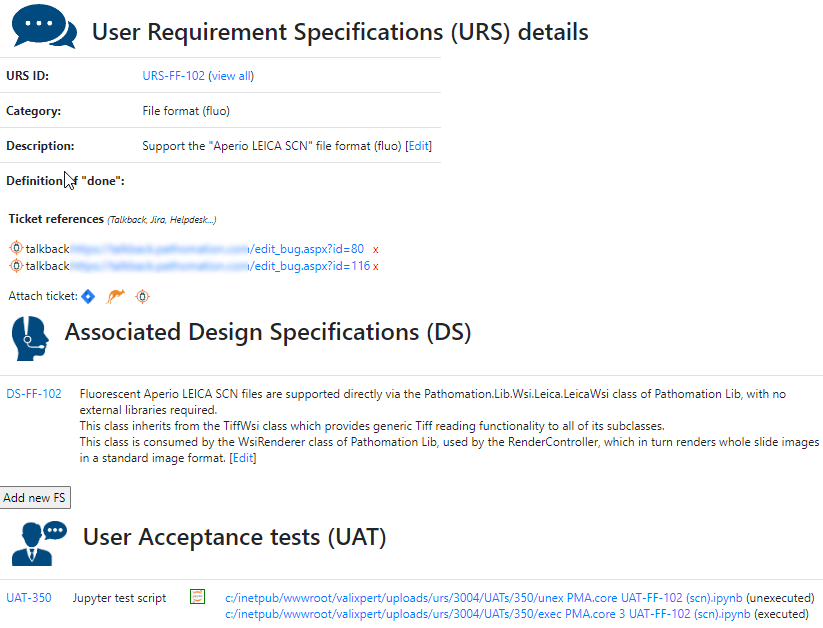
We have all information in a single page. What a difference from a few years ago, where we had to puzzle these pieces together from several Word-documents.
When are you done with your software? When you’ve written sufficient tests to prove that all your user requirement specifications effectively work as intended.
Risk assessment and testing
In order to get a grasp on what “sufficient” testing means, a risk assessment has to occur first.
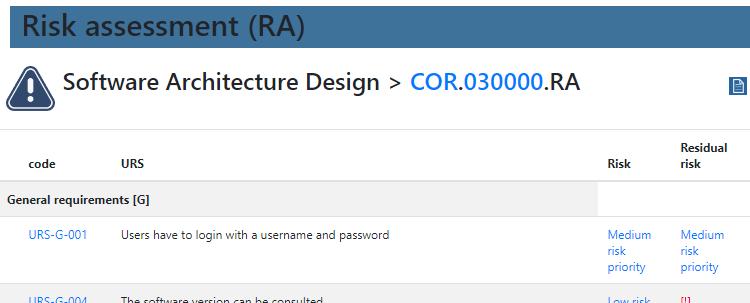
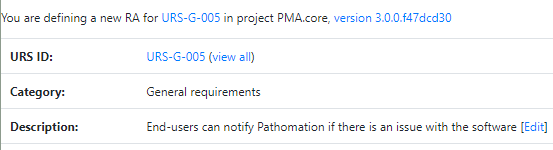
We provide product owners with a wizard-like approach to determine the risk analysis for each URS individually. Let’s have a look at this one:
The Risk Analysis then becomes as follows:
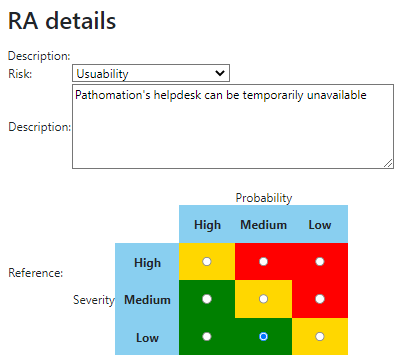
Do this for each URS, and you can come up with a granular test plan. In the future, we’d like to couple this back to the URS detail screen itself: A feature with high-risk, should have 3 tests; a feature with medium-risk, should have 2 tests; and a feature with low-risk can be sufficiently documented by providing a video.
Reporting
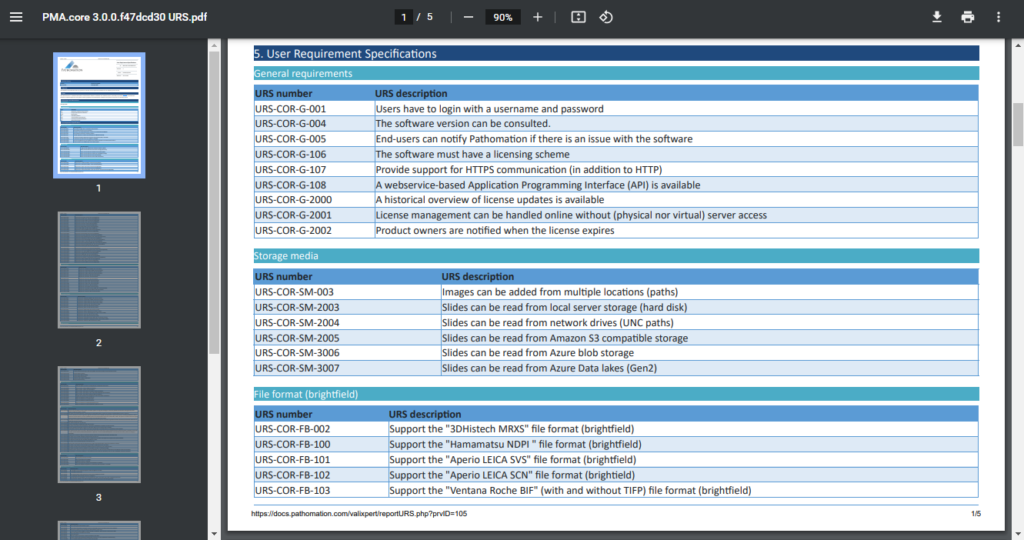
Remember our original Word-mess?
We (and you too) still need these documents at the end of the day for filing. You can complain about paper generating, but when to think about it: it absolutely makes sense to still produce these textual snapshots.
Just look at it from the other side: Imagine you’re a regulatory agency and you get applications from 100 companies. Each company deposits a database and a set of scripts to interface it with the message “oh, just get the scripts up and running and you’ll get all our information. it’s super-easy, barely an inconvenience”. The only alternative then is for the agency to provide its own templates for all 100 companies to fill out.
Luckily that direction is easy from where we’re standing. What we do to provide the necessary regulatory documentation is extract the proper information from the database, format it properly as HTML, and then print those webpages to PDF documents.
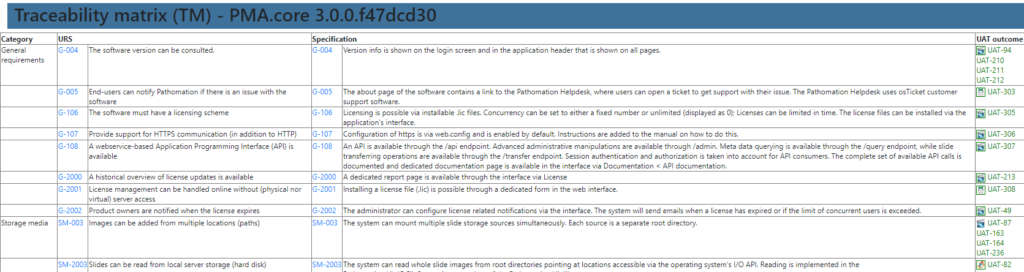
A traceability matrix? Well, that’s just a matter of a couple of outer joins and summarize the outcome in a table.
Documentation. Validation. Done.
What’s left?
We used the technique described in this article to obtain our self-certified CE-IVD label for our PMA.core software.
We also worked with external independent consultants to make sure that our technique would indeed withstand outside scrutiny. After all, any software developer can self-certify their own software.
It’s important to note that in addition to keeping track of a number of documentation items, we also performed a validation study in two hospitals, with two different slide scanners. This confirmed everything we did so far, indeed applied to a clinical setting as well.
Now it’s onto PMA.core 3.1. This will be a minor release, with a focus on additional security features like LDAPS and improved IAM / EC2 integration.
For PMA.core 3.1, we’re not doing the whole process described in here from scratch. How we solve this problem then in an incremental fashion, is food for a next article.