
The case for simplicity
Sometimes user requests are simple. In this particular instance, we had a customer that “just” wanted a list of all of their slides (within a particular root-directory).
We pointed them to the repository of PMA.control:
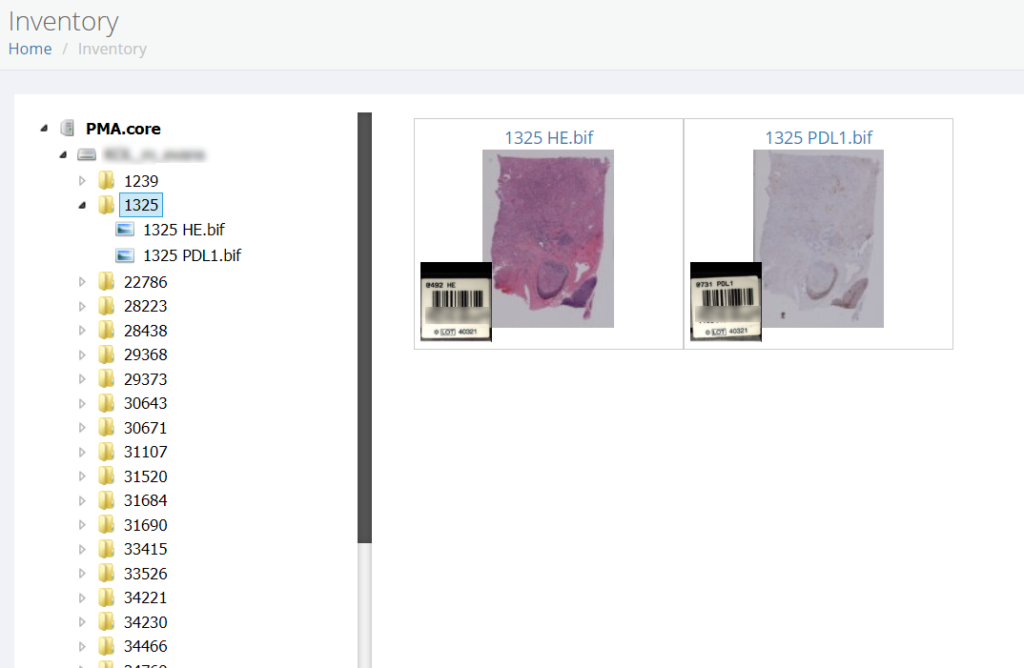
We pointed them to the tree interface that combines folder and slides in PMA.view:
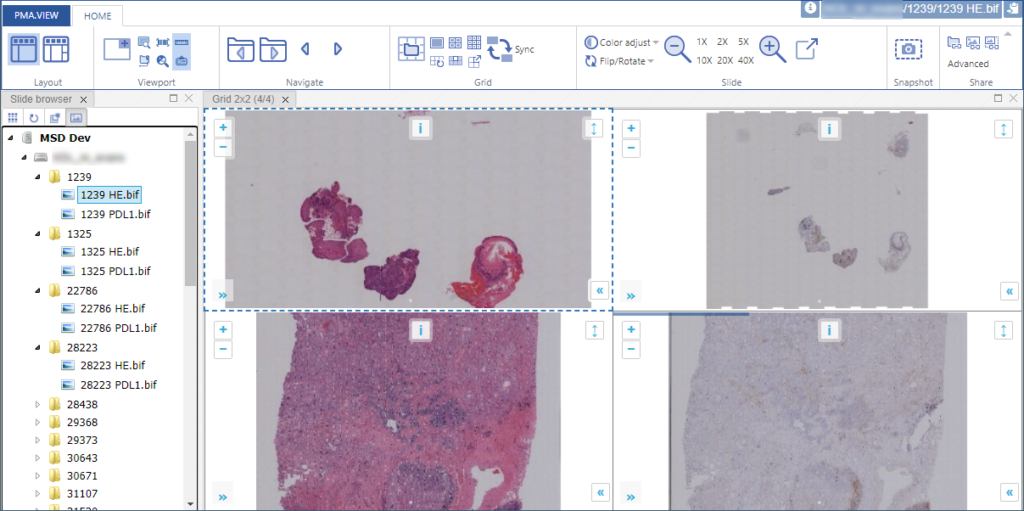
But as it turned out, these were too complicated. The customer already had built a nested hierarchy of folders and subfolders, but now wanted a linear list of all slides across all folders. A thumbnail next to each slide reference would also be useful, thank you very much.
A linear list of slides
Here’s how we can create a linear list of slides:
from pma_python import core
from datetime import date
from os import mkdir
from os.path import exists
core.connect()
slides = core.get_slides("C:/slides", recursive=True)
print(len(slides), " slides found") # sanity check
f = open("c:/wsi_report/cat1.html", "w+")
f.write("")
f.write("Market slide catalog created on " + str(date.today()) + " ")
f.write("")
for slide in slides:
f.write(slide + "
")
f.write("")
f.write("")
f.close()
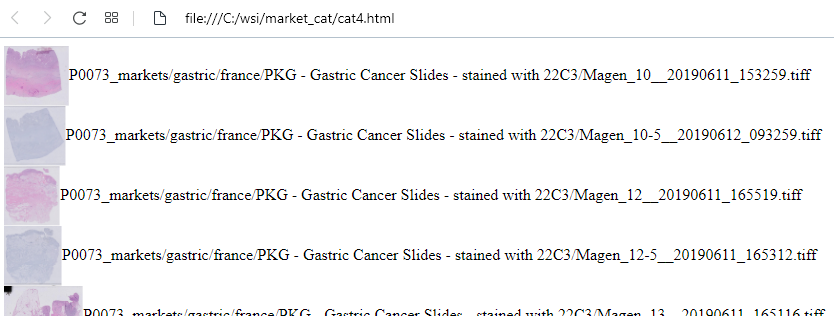
Want to include the thumbnail? Look no further than the get_thumbnail_url method:
f = open("c:/wsi_report/cat2.html", "w+")
f.write("")
f.write("Market slide catalog created on " + str(date.today()) + " ")
f.write("")
for slide in slides:
thumb = core.get_thumbnail_url(slide)
f.write(" " + slide + "
" + slide + "
")
f.write("")
f.write("")
f.close()
Ah crap, that looks horrible!
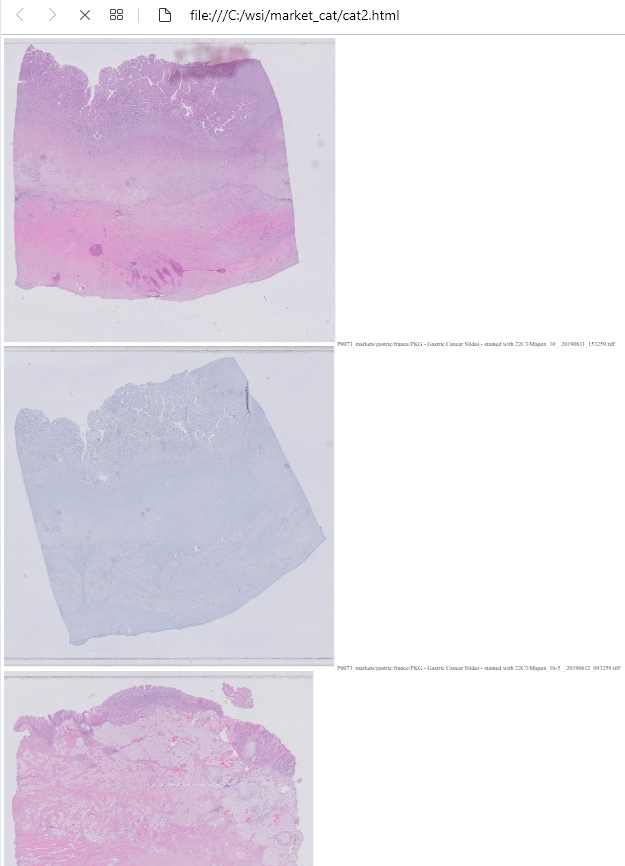
No worries; just add some formatting to the ole’ <img> tag:
f = open("c:/wsi_report/cat3.html", "w+")
f.write("")
f.write("Market slide catalog created on " + str(date.today()) + " ")
f.write("")
for slide in slides:
thumb = core.get_thumbnail_url(slide)
f.write("" + slide + "
")
f.write("")
f.write("")
f.close()
Yes, something like this:
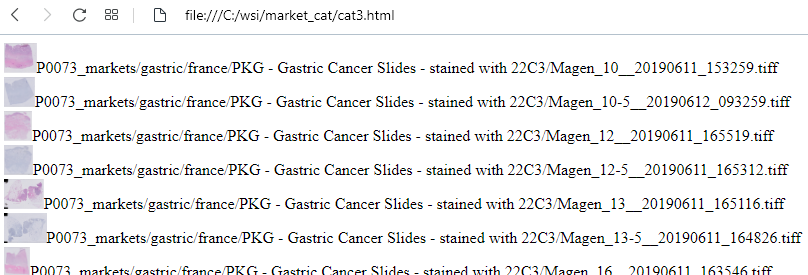
Much better!
But there’s a catch here: careful observers notice that the thumbnail URLs used by the above code have a PMA.core Session ID embedded. This means that those URLs are only valid as long the respective Session IDs remain valid.
This is fine for ad-hoc reporting, but if we want a list that we can post somewhere on a central server as a reference source for others, we need something just a little more sophisticated. Yes, the keyword in this post is “just”, just in case you’re wondering.
Creating a persistent slide catalog
We want to create a list of all slides in our repository, and we want to list to be persistent. In other words, it is not ok to walk away from our browser for a couple of hours, refresh our list, and see the following:

The solution is to not use the thumbnail URL, but retrieve each thumbnail as a binary object and save it to a subfolder. Then, we let our <img> tag point to the downloaded (or cached, if you will) files.
dir = "c:/wsi_report/cat4/"
if not exists(dir):
mkdir(dir)
f = open("c:/wsi_report/cat4.html", "w+")
f.write("")
f.write("Market slide catalog created on " + str(date.today()) + " ")
f.write("")
for slide in slides:
thumb = core.get_thumbnail_image(slide)
fn = core.get_slide_file_name(slide) + ".jpg"
thumb_fn = dir + fn
print("Saving thumbnail as ", thumb_fn)
thumb.save(thumb_fn)
f.write("")
f.write(" ")
f.write("" + slide + "
")
f.write("" + slide + "
")
f.write("")
f.write("")
f.close()
This catalog fits our needs. We can post it anywhere, and it only relies on local data. You can store it on your hard disk. You don’t need PHP, you don’t need Python, you don’t need the underlying PMA.core (PMA.start in our example code) to be up and running.
There are cons to our approach, too:
- The catalog takes longer to generate, as we need to download a large number of thumbnails one by one
- The catalog takes up more space. In our case, for 265 slides, we went from 197 KB to 20+ MB. That’s still manageable to send in a zipped file package, but for larger repositories may become inconvenient.
- The catalog is a snapshot of the repository. If you use as a reference today and add slides to the underlying root-directory tomorrow, the catalog will not pick up the newly added (or removed, for that matter) slides, unless you re-generate the catalog and re-distribute or publish it.
And finally
Every solution has trade-offs, and even for simple problems, you have think through things to come to the right solution. Problems that have the word “just” somewhere in their formulation can be particularly trickly.
The sourcecode for this post is available through our repository as realdata 038 – simple slide catalog.ipynb. Feel free to download it and adjust it for your own needs.
As always: we encourage interaction. Do let us know what digital pathology problem or scenario you want us to work out in one of our next posts!