
By filename
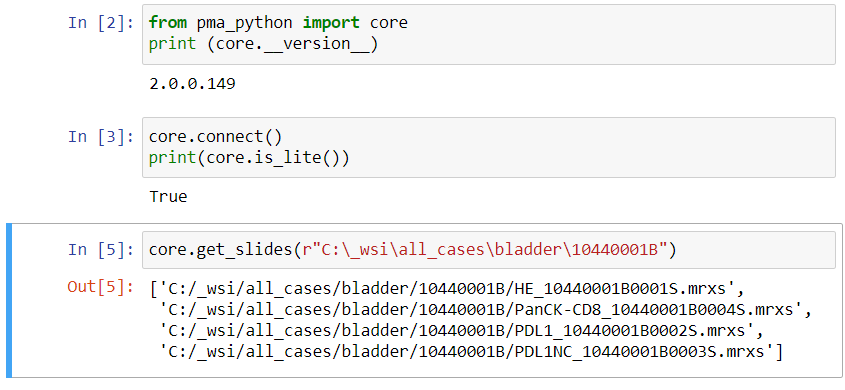
The most straightforward way to identify a slide is by its filename.
When you request the slides that are in a subfolder, you get a list of filenames back. Each filename refers to a slide.
By Unique Identifier (UID)
Once you obtain a filename referring to a slide, you typically want to do something with it.
Using filenames as references throughout your software is problematic however, for a variety of reasons:
- A full path reference can become really long, and may not fit a field. No matter how careful you are, at some point there’s always that 51-character string that just won’t quite fit into the varchar field that was defined with a standard field size of varchar(50)
- Unicode-encoding can be tricky, and many languages complicate matters further by providing different methods for querystrings, querystring parameters etc. Not to mention the databasefield that you forgot to make nvarchar instead of varchar. Good luck chasing that one!
- Using filename references is just not safe. Imagine that you’re passing on a URL that looks like lookAtMySlide.jsp?slide=case35%2fslide03.svs… It’s all too easy (or even tempting) for the recipient to want to try out variations on that scheme: “hmm, I wonder what slides 2 and 4 look like?” or “let’s have a look at cases 1-34 too”
For this purpose, we’ve introduced the UID-principle. A UID is a 6-character random string, tied to a particular slide in a particular location (folder). The UIDs are generated by the PMA.core engine, so there’s no collusion possible between UIDs referring to different slides. By their nature, there’s no sequential logic to them either, so there’s no point wondering asking information about slides YT4TGQ or YT4TGS, after finding out slide YT4TGR exists.
You can retrieve the UID of any slide through the GetUID() method. For this, you’ll need an instance of PMA.core, because slide anonymization is not supported by our free PMA.start viewer.
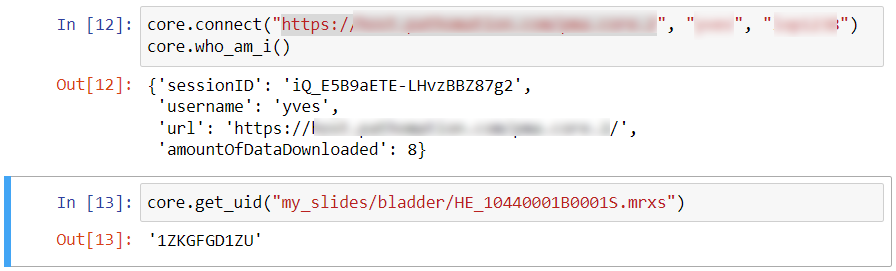
If you’ve had a look at our API calls and SDK methods, you’ll notice that many calls have a parameter argument PathOrUid, rather than just Path. This means that each time you specify a filename to identify a slide, you might as well make life a bit more easy on yourself (as well as possibly your compliance department!) and use the UID parameter instead. Have a look then at the following semantically identical calls:

The one notably exception to this would be the invocation of the GetUID() method itself, of course. But don’t worry; you can’t accidentally request the UID of a UID. If a slide reference passed on doesn’t refer to any existing content, you’ll just get a runtime error instead.
By Fingerprint
UIDs are great, but what if you want to track virtual slides? Physical slides aren’t static and move around; this real-life environment is oftentimes mimicked in the virtual world, where a lifecycle of a slide can go like this:
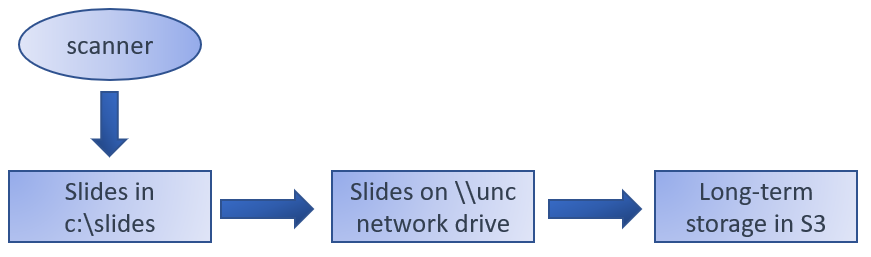
Different systems may be responsible for the different types of movement, making it very hard to track the virtual slide’s lifecycle in its entirety.
This is where a slide’s fingerprint can come in handy. Unlike a UID, the fingerprint is a signature string that is calculated based on a slide’s actual characteristics. We have a whole separate article on the subject.
The bottom line is that when you have new_slides/slide17.svs, and you move it to validated_slides/slide17.svs, you’ll be able to identify these slides as being identical through their fingerprint signature.
Let’s say that we have a slide slide54123.mrxs in the incoming folder, that get subsequently moved (and renamed) to a folder related to bladder research, to finish its lifecycle in an archival folder.
Have a look at the following code then:
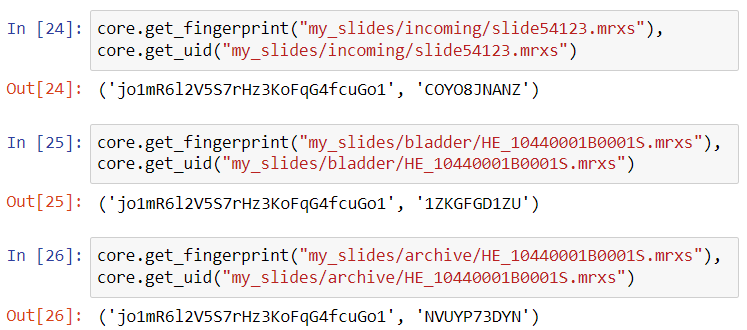
Note that the UID is different for all three slides, but the fingerprint remains the same, even as the filename changes!
And you can use this for even more applications:
If you’re later wondering if new_slides/slide17.svs is a re-scanned slide, or whether it’s just the original slide that somebody forgot to delete, you can also use the fingerprint for this. If it is the old version that is just lingering, it will still have the same fingerprint. However, if it’s a newly re-scanned version of the physical slide, the fingerprint will be different, due to subtle changes in the image capturing process. It’s interesting to note than that in the latter case, the UID will still be the same.
Why would you still use UID instead of a fingerprint signature? B/c a fingerprint takes some time to generate: a slide must actually be (at least partially) and analyzed to obtain its fingerprint. The UID in contrast is only a random string that is generated in a split second. In many cases, all you want is a point to a slide. For a variety of reasons, the UID is then a faster alternative.
By barcode
Virtual slides comes from physical slides, so how did people identify slides before the advent of technology? Well, first they invented the are on the slide that we now refer to as slide label, and coated it with a material they could easily write (typically in pencil). Later on, label printers were introduced, and in combination with bio-repository systems provided by the (AP)LI(M)S, random (bar)codes could now be imprinted on small stickers that could be pasted on the slides directly, so that no scribbling was necessary anymore.
The idea is that the barcodes are machine-readable, and could be used to match all sorts of information afterwards, at the same time guaranteeing anonymity of the slide itself (a barcode identifier only makes sense in the context a particular hospital / lab / (AP)LI(M)S / biorepository).
A barcode in many ways is the real-world equivalent of a UID, but it doesn’t have to be. Consider this:
- There can be structure to encoded barcodes, most often sequence information
- The barcode can still encode certain patient or doctor information, though this is rather rare. People aren’t doing this anymore because of practical concerns, as a barcode only holds a limited number of characters.
- Unlike UIDs, barcodes can take on all sorts of shapes and forms, making it difficult to provide universal identification services
- You can have more than one barcode on a slide
- The barcode can still be pasted on manually at an angle, which can make it hard for machines to recognize, whereas a human lab technician in such a case would just rotate her hand-scanner a bit.
- The barcode can be applied to a slide before it goes through a series of chemical steps, that can in turn degrade the barcode and make it less legible
Even with the above caveats, we don’t argue the value of barcoding per se. It’s definitely way better than the alternative (pencil, scribbling). At the same time, barcoding makes most sense within a setting of one lab (or lab-group), one set of hardware, and one (AP)LI(M)S, so that the entire pipeline can be calibrated to a (beforehand agreed-upon) specific format.
At Pathomation, we offer the possibility to extract barcodes from label images through the GetBarcode(). We have our basic implementation in such a way that it works on a wide variety of labels:
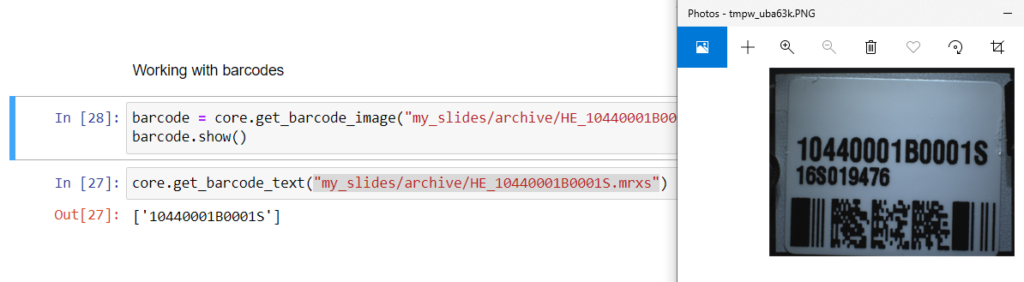
Another way to study this behavior is via the debugger in your webbrowser:
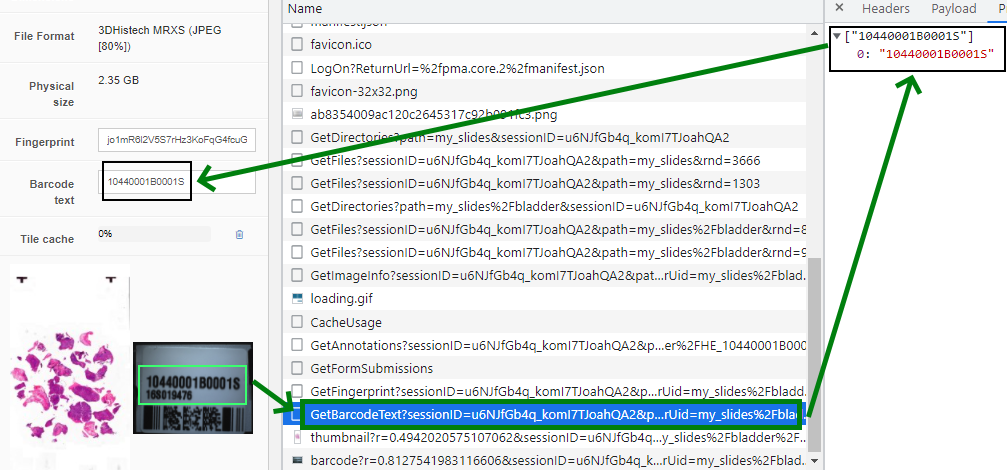
The thing about barcodes is unfortunately: it’s not waterproof. The resolution of your scanner may not be high-quality enough, and there are a number of other reasons it can still go wrong. We’ve seen stupid things happen, like the number “1” being interpreted like the lowercase letter “L” etcetera.
You can use the existing implementation for test scenarios. However, for production environments, we should be involved in the IQ /OQ / PQ loop, so we can advise properly on how best to roll this out. When you know that your identification scheme only includes numbers, we can configure the recognition engine to not accidentally pick up letters (and prevent a 1 > l switch from ever happening in the first place).
In summary
At Pathomation, we pride ourselves with the slogan “digital pathology for pathologists, by pathologists”. We know of the struggles to identify and keep track of slides, both physically and virtually. Therefore, we offer different ways of identification. We’ve published content on this before, but this is the first article in which we neatly outline all options next to each other.