A new year starts with good intentions. For me, the new year 2018 in part started with the realization that it’s been forever that I’ve written anything on the RealData blog.
I like writing. I like passing on knowledge. So the most pertinent question to ask then perhaps is: why did I stop?
Let’s start with the obvious one: lack of time. Getting content out in the right format is hard. It’s one thing to jot down some notes in a diary (a jupyter notebook perhaps); it’s quite another to deliver a publishable readable blog-entry.
And after all: what’s the point, right? Who reads this anyway? You? Why? Do I even have anything to tell you?
I think my journey is still worth sharing. So let’s look at some of the things that went wrong and contributed to my preliminary failure:
I slacked off on the online courses I was planning on taking back in April 2017. Perhaps even worse: I wasn’t passing anymore. At least not as easily anymore as I did in the beginning. Why was that?
I’m now convinced that taking online courses is an art in itself. It’s really easy to go to edx.org, or Coursera, or Datacamp, or any other platform and have the intention of “Let’s take every data science course there is and become a data scientist”. They all look so interesting, right?
I remember passing the Datacamp course Introduction to Python for data science (aka “Python for beginners”) in two days, with a 99% final score.
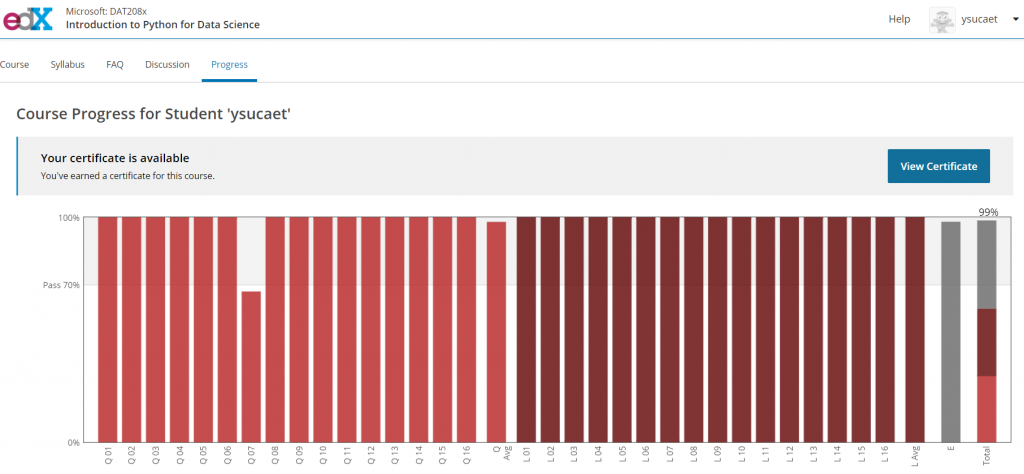
I started struggling really bad taking the advanced Programming with Python for data science course. Again: why? Because anyone who’s been programming for over 25 years can probably pass any beginning programming course in any language. I was forgetting that I’m pretty proficient in C# today because I have been using it ever since the very first European .Net conference in Copenhagen, Denkmark in 2001.
In order to become a proficient Python programmer, I have to start using the language myself in daily tasks. An obvious one, I’m afraid, but saying it is easier than doing it. There’s a level of humility attached to this: it’s hard for me to spend half an hour trying to figure out how to process something as trivial as a text file in Python, when I *know* I can write the same script in PHP in 5 minutes. Hey, I can probably do it with a console application in C#, too!
A few years ago, I was mentoring someone into software development. The person was highly educated, had some scripting experience with Excel VBA, and seemed ready for the next level. At one point I was looking something up for her on StackOverflow when she commented “oh, so programming is just copy/paste, right?”. Well, yes and no. Mostly no, of course. But websites like StackOverflow can make it look that way. And sometimes we fool ourselves into thinking that it really has become that easy. It hasn’t
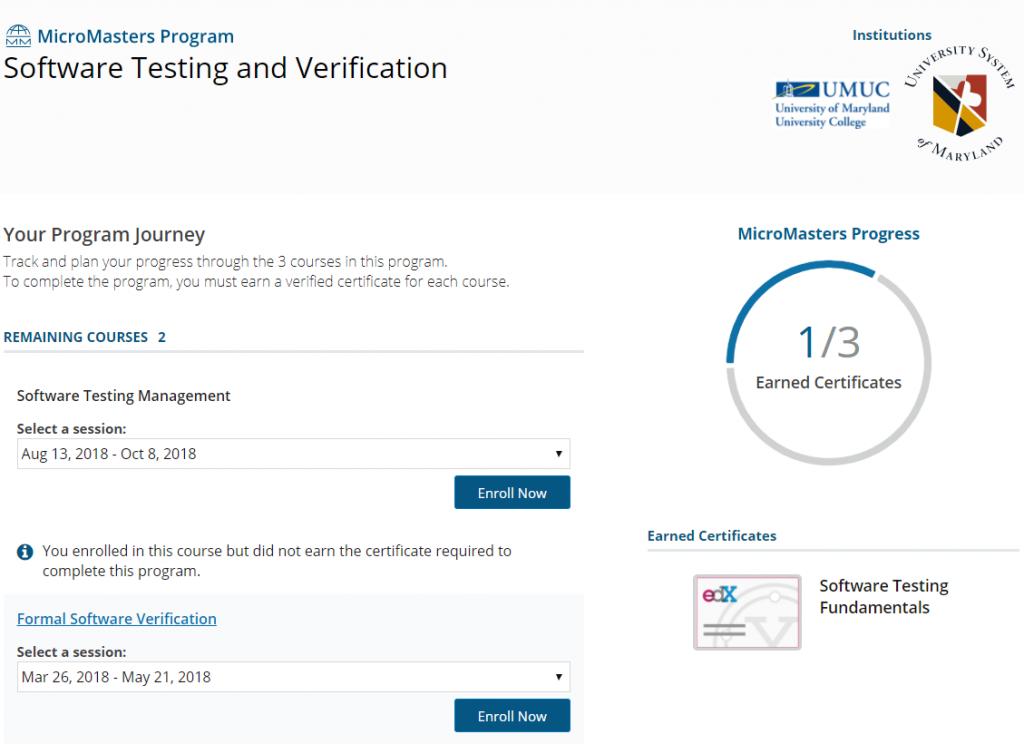
At around the same time that I was flunking my advanced Python curriculum, software testing was rapidly become a top-priority at Pathomation. Huzzah, edx.org also appeared to have a “micromasters” track in software testing. This track consisted of only 3 courses, which seemed more manageable than the entire data science track.
I took the first course and passed. I should point out that these are academically organized courses, considered to be graduate level, and passing them is actually somewhat tough: you have to get an 80% in order to get the certificate.
Unfortunately, the testing curriculum went the same way as the data science curriculum I signed up. I passed the first course; but slacked off halfway during the second course. There’s only so much coursework your brain can process in any given timeperiod, too.
They say that good intentions have a higher success rate of being realized when you write them down. So, here’s my intention for 2018: I’ve backed up a little and given it some consideration of why I failed in my attempts last year.
So let’s take a reboot now and set out to complete the following courses and education tracks in 2018:
- Microsoft Excel for the data analyst XSeries program (more on that in a next post)
- Andrew Ng’s machine learning course
- Fast.IA deep learning course
- Andrew Ng Deep learning course
Curious to see if I’ll make it this time? Keep following this blog, then!